색인

Python sklearn 파이프라인이란 무엇입니까?
ColumnTransformers는 강력한 기능이지만 열을 여러 단계로 처리해야 하는 경우 충분하지 않습니다.
파이프라인 기능은 복잡한 프로세스를 단계별로 처리할 수 있도록 여러 트랜스포머를 체인으로 연결합니다. 앞에서 배운 ConlumnTransformer 함수도 파이프라인의 체인에 넣을 수 있습니다.
이 문서에 사용된 예제에서는 다음 구조를 사용합니다.
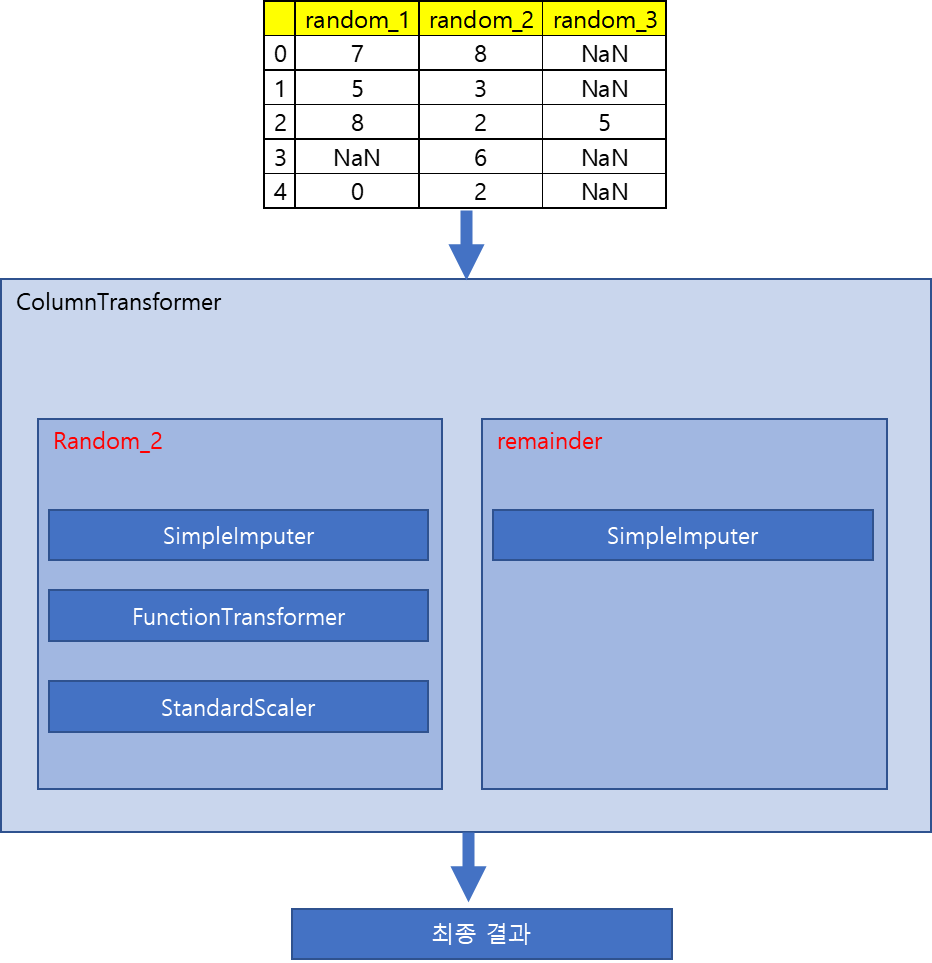
그림에서와 같이 Non 값은 3×5 행렬에 무작위로 삽입됩니다.
ColumnTransformer를 사용하여 데이터를 원하는 형식으로 처리합니다.
이 시점에서 사용자는 필요한 열만 선택하여 파이프라인에 넣습니다. 여기에서 Random_2 열의 값과 나머지 단순 입력 값을 파이프라인에 넣습니다. random_2 열은 파이프라인에 열거된 SimpleImputer, FunctionTransformer 및 StandardScaler 함수를 순서대로 적용합니다.
실제 사례를 통해 쉽게 이해해 보자.
Python sklearn 파이프라인 예제 실습
샘플 코드는 기사 하단에서 다운로드할 수 있습니다.
전체 샘플 코드>>
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import FunctionTransformer
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
data_df = pd.DataFrame({
"random_1":np.where(np.random.uniform(0,1,5)<0.3, np.nan, np.random.randint(0,10,5) ),
"random_2":np.where(np.random.uniform(0,1,5)<0.3, np.nan, np.random.randint(0,10,5) ),
"random_3":np.where(np.random.uniform(0,1,5)<0.3, np.nan, np.random.randint(0,10,5) ),
})
col_transformer = ColumnTransformer(
(
(
"random2_Pipeline",
Pipeline((
("MeanImputer" , SimpleImputer(strategy="mean")),
("LogTransformation", FunctionTransformer(lambda value: np.log1p(value)) ),
("StdScaler", StandardScaler() ),
)),
("random_2")
),
),
remainder=SimpleImputer(strategy="constant", fill_value=7)
)
print(data_df)
col_data_df = col_transformer.fit_transform(data_df)
print(col_data_df)
print(type(col_data_df))
결과>>
random_1 random_2 random_3
0 6.0 7.0 NaN
1 4.0 9.0 5.0
2 6.0 2.0 9.0
3 2.0 NaN NaN
4 NaN NaN 8.0
(( 0.50078424 6. 7. )
( 1.04602424 4. 5. )
(-1.89582252 6. 9. )
( 0.17450702 2. 7. )
( 0.17450702 7. 8. ))
<class 'numpy.ndarray'>
코멘트>>
data_df = pd.DataFrame({
"random_1":np.where(np.random.uniform(0,1,5)<0.3, np.nan, np.random.randint(0,10,5) ),
"random_2":np.where(np.random.uniform(0,1,5)<0.3, np.nan, np.random.randint(0,10,5) ),
"random_3":np.where(np.random.uniform(0,1,5)<0.3, np.nan, np.random.randint(0,10,5) ),
})정수 임의 값으로 Pandas DataFrame 집합을 만듭니다.
where 함수를 사용하여 0과 1 사이의 실수 5개를 만들고, None에 0.3보다 작은 값을 삽입하고, 나머지는 0과 10 사이의 정수 5개로 채웁니다. 결과는 다음과 같이 생성됩니다.
random_1 random_2 random_3
0 6.0 7.0 NaN
1 4.0 9.0 5.0
2 6.0 2.0 9.0
3 2.0 NaN NaN
4 NaN NaN 8.0
col_transformer = ColumnTransformer(
(
(
"random2_Pipeline",
Pipeline((
("MeanImputer" , SimpleImputer(strategy="mean")),
("LogTransformation", FunctionTransformer(lambda value: np.log1p(value)) ),
("StdScaler", StandardScaler() ),
)),
("random_2")
),
),
remainder=SimpleImputer(strategy="constant", fill_value=7)
)전체 코드는 ColumnTransformer와 함께 작동합니다. 파이프라인과 나머지는 그 아래에 놓습니다.
파이프라인은 (random_2) 열에서만 작동합니다. 애플리케이션 콘텐츠는 SimpleImputer, FunctionTransformer, StandardScaler입니다. 나머지는 SimpleImputer를 사용하여 값이 아닌 것을 7로 채웁니다.
print(data_df)
col_data_df = col_transformer.fit_transform(data_df)
print(col_data_df)
print(type(col_data_df))결과를 인쇄하십시오. ColumnTransformer에 의해 출력되는 값은 numpy ndarray 배열 형태로 변경되며 이전에 파이프라인이 적용된 컬럼이 첫 번째 컬럼이 되므로 주의하여 사용하시기 바랍니다.